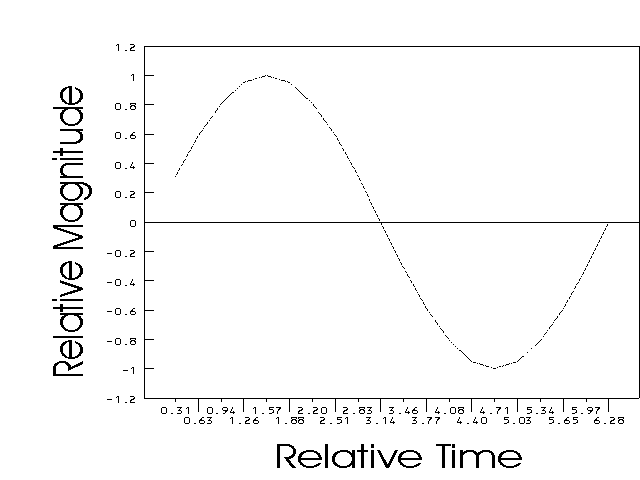
There are many factors involved in choosing and using digitized speech samples. To begin we will look at what digitized speech is, and how one gets it. Speech is an instance of sound that society has given meaning to. Sound is a wave distortion through a medium usually consisting of air. This wave may consist of multiple frequencies of sound, as shown in the digitized speech example (see Figure 18). It is possible to look at a pure tone sound (a single frequency of sound) in terms of a sinual wave [DC93][DS86] with a period of 1/frequency. The process of taking a wave and converting it into a sequence of representative numbers can be demonstrated in an easily understood fashion. The first step is to take the wave form and place it within a time and amplitude framework (see Figure 14).
Figure 14: Sine Wave Show Within an Arbitrary Measuring Framework
The next step is to select the sampling rate (e.g. CD's sample at 44000 samples per second)[DS86]. The sampling rate is converted to frequency (1/rate) and used as the interval of time for the X axis. The Y axis is some arbitrary unit of measure, often from -1 to 1. This result is incorporated into Figure 14. We next mark the points on the wave that intersect the time interval marks (see Figure 15).
Figure 15: Sine Wave With Intersection Points Marked
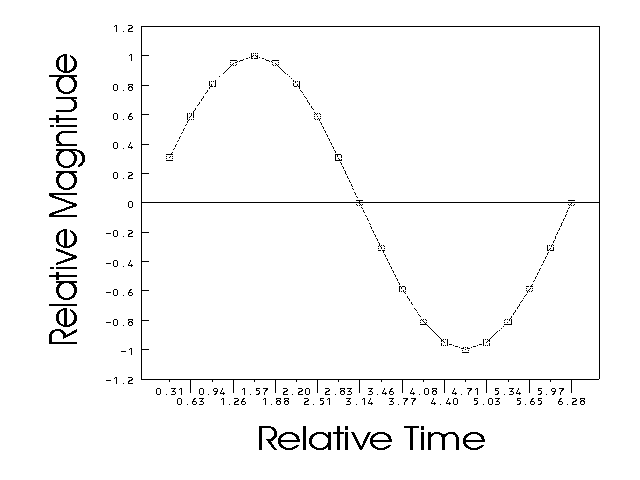
These sample values form an instantaneous mapping of the waveform, which is taken as the set of values over the whole time (1/rate) interval. This gives us a new graph of the waveform that we are considering (see Figure 16).
Figure 16: Graph of Digital Rendition of Original Waveform
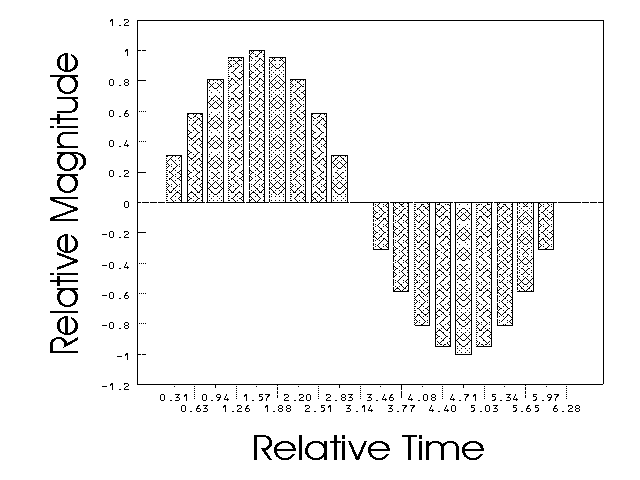
We then apply a scale function to convert these real numbers into an integer range. In this case the function applied was New Value = INTEGER ((Original Value+1)*128) (shown in Figure 17).
Figure 17: Final Rendition of Waveform That the Computer Will Use
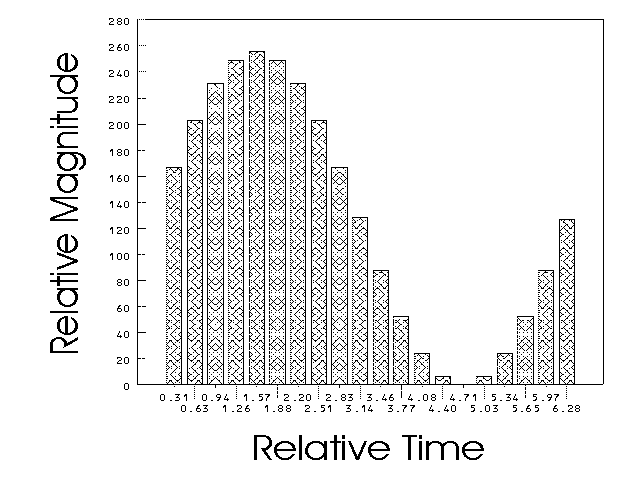
These numbers are then taken sequentially and stored with the sampling rate into a file for future playback.
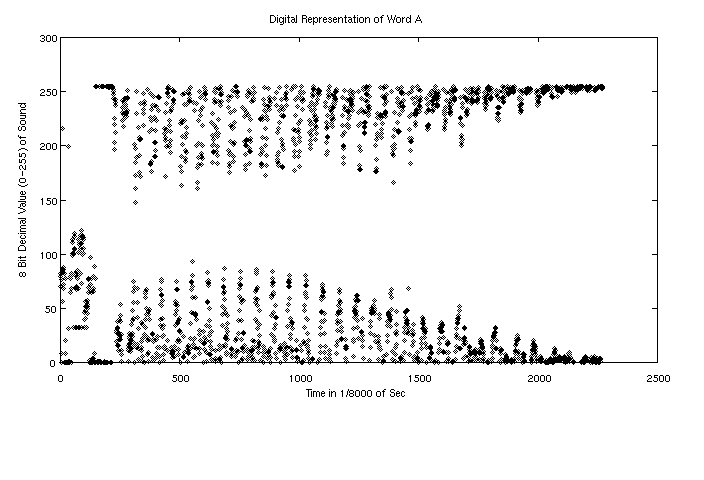
Now that we know what digital sampling is we need to select a sampling rate. Clearly the 44000 samples per second of a CD player is sufficient, however, we would like to find a more space efficient solution. Some research led us to the value of 8000 samples per second because it is the rate of the American Telephone Standard[WG89] and a rate which speech pathologists use for help in detection and correction of speech disorders[DC93]. This rate was used and a graphical representation of the word A is shown in Figure 18.
Figure 18: Digitized Graphical Representation of the Word A
Previous Section Next Section Return To Thesis Home Return To Home Page